Discover how today’s most successful IT leaders stand out from the rest. Read the report
How to build stable, accessible data infrastructure at a startup
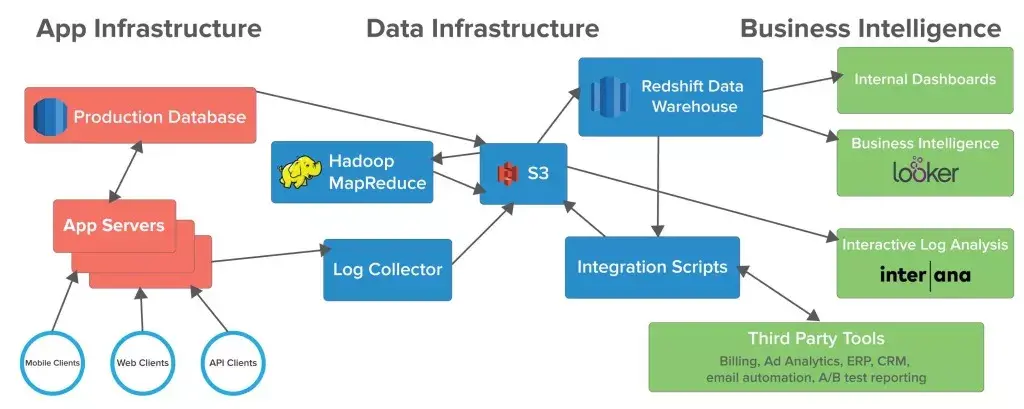
Data is a core part of building Asana, and every team relies on it in their own way. Our growth team relies on event data to analyze experiments (A/B tests). We build many quick experiments — we often have many in flight at once — and let the impact on engagement and other key metrics guide us on which ones to abandon and which ones to invest in. PMs, designers and product engineers investigate usage data to help inform inevitable tradeoffs like simplicity vs. power. Through this we understand which new product directions could unlock the most potential. Marketing needs clarity on which of its campaigns are driving new users to Asana. Finance requires extremely robust statistics about our overall growth patterns to help ensure Asana will be around in 2064. How do you build one system to support all those diverse needs?
Starting small and scaling over time
The above diagram isn’t what we built initially; we started out with a much simpler system: basically a bunch of python scripts and MySQL all running on one box. At first, a simple system can reduce the maintenance of the system, and if you don’t have any users yet, you may want to start there too. But Asana’s grown steadily since launching in 2011 (see graph of events below), and we started to hit a lot of limits. Recently, we’ve made a series of changes to our data infrastructure that have all proven extremely valuable:
Investing in monitoring, testing, and automation to reduce fire-fighting
Moving from MySQL to Redshift for a scalable data warehouse
Moving from local log processing to Hadoop for scalable log processing
Introducing Business Intelligence tools to allow non-experts to answer their own data questions
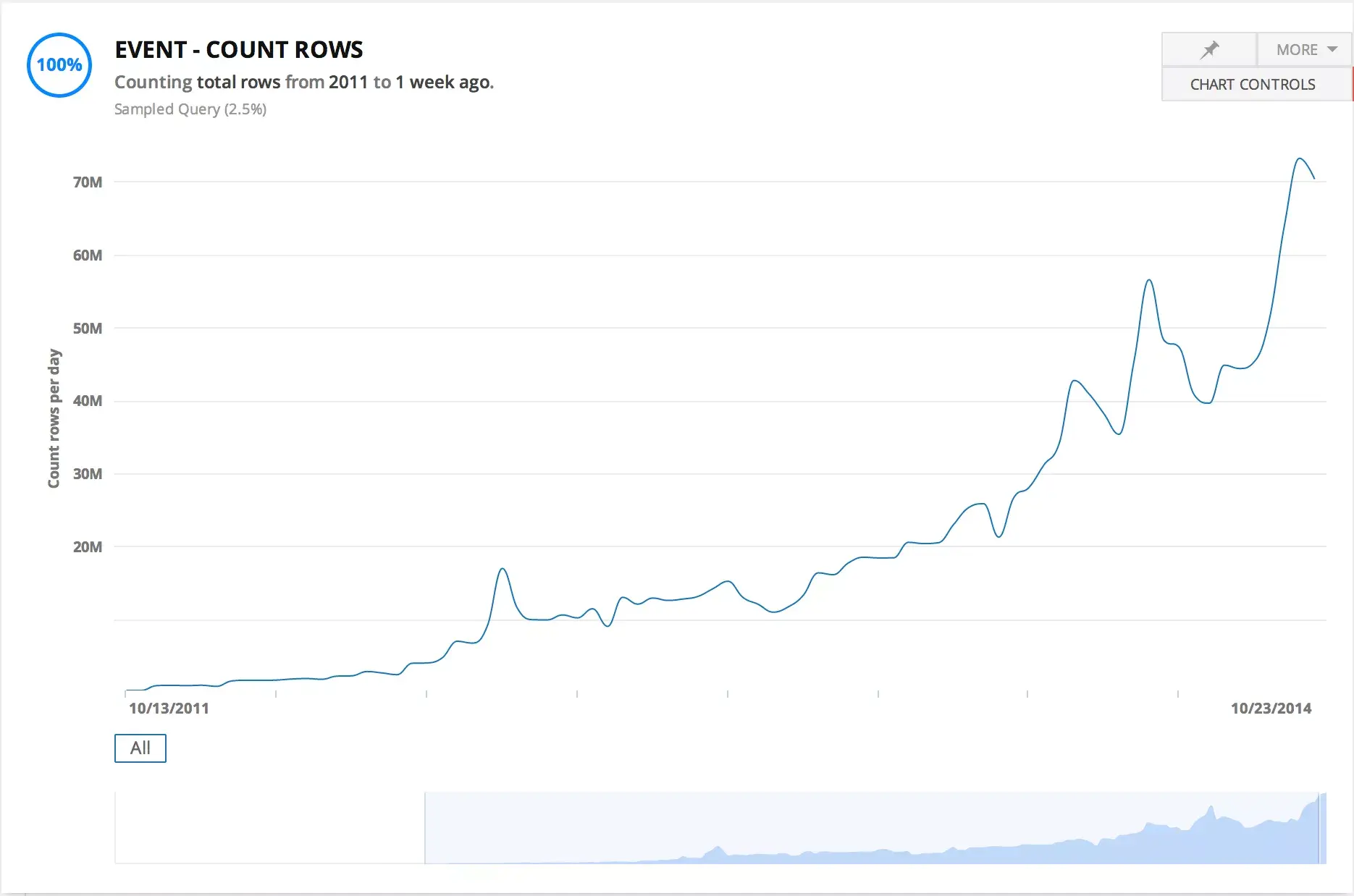
The graph of number of “events” moving through Asana over time; a measure of raw data volume.
Ending the endless fires
A year ago, we were facing a lot of stability problems with our data processing. When there was a major shift in a graph, people immediately questioned the data integrity. It was hard to distinguish interesting insights from bugs. Data science is already an art so you need the infrastructure to give you trustworthy answers to the questions you ask. 99% correctness is not good enough. And on the data infrastructure team, we were spending a lot of time churning on fighting urgent fires, and that prevented us from making much long-term progress. It was painful.
Getting Inspired
When bad things happened, we ran a 5 whys to uncover the root cause and fix it. For example, we once had a data processing script write an error log file so large we failed to email the log contents. In response, we began truncating the log file before emailing and alerting on email failures, and added monitoring on the output of the script. In other cases where we didn’t have enough insights to understand what happened, we would add logging, monitoring and alerts. For example, when our experiment processing was frequently falling behind, we added extensive logging at different processing stages to see where it was spending most of its time, and used that to inform which portions to optimize.
When our monitoring and logging were insufficient, the worst fires went on for months. In one particular example, one of our jobs was taking significantly longer than it used to. After a long time, we figured out that some queries were being passed a datetime object with specific timezone info that for reasons we still don’t fully understand dramatically increased query time. With this job taking longer than a day to finish, the next day’s job would start and cause MySQL lock timeouts. When graph generation finally ran, those jobs never had all the data they needed. We cached zero values, and had to do a significant amount of manual work to clean that up each time. Failures propagated into further failures, so patches proved unsuccessful. Ultimately, this incident inspired us to truly prioritize testing.
A year ago we had almost no tests in our data infrastructure code. While we’re still not proud of our test coverage, we’ve made a lot of progress. It’s awesome when you get a test failure and realize what could have broken had your change gone to production. We use Python’s built-in unittest module, although we’ve been exploring the features nose adds. We’ve focused our efforts here on low hanging fruit, especially in the areas where we can build out framework code for enabling our data scientists and other data consumers to write their own tests.
Automating Investigation
We used to run everything via cron. Jobs would run at different times, and we’d hope they finished before jobs that depend on them started. When that wasn’t the case, e.g. a job crashed, there would be a lot of manual cleanup. Then we started using Luigi to build a pipeline that understands and respects the dependencies, as you can see with a small subset of our pipeline below. With Luigi, when a job fails, we get alerted about it and its dependencies aren’t run until we fix the problem. It’s really easy to resume the pipeline and have only incomplete jobs run. This was also our first step towards parallelizing these jobs.
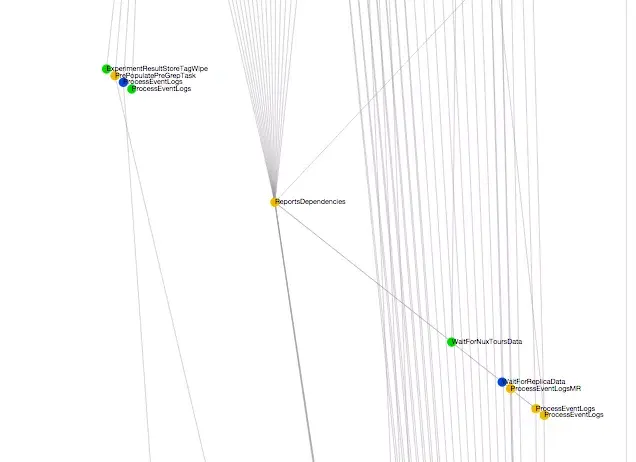
This is a diagram of our data ETL pipeline as diagrammed by Luigi
Our alerting used to be very crude. We had the obvious alerts like available disk space, but it’s taken a lot of thought and fighting back against the pain to get everything we have today. We now cover all system alerts from memory/CPU usage to elongated periods of high load on our Redshift cluster. We monitor progress of our data pipeline, alerting when it takes longer than expected or when some jobs haven’t completed by the time we expect them to. We monitor the data itself, making sure critical values are non-zero and using regression analysis to alert when an event is logged a lot less or a lot more than we’ve seen in previous weeks.
We improved our process around triaging email alerts. We rely on Asana heavily for this, which works especially well in sharing the burden and notifying consumers of the data when things are known to be broken.
Will all this investment, the fires started to cool. Once we weren’t spending time keeping our existing data infrastructure from falling over, we had time to build the future.
Our Latest Evolution of Data Infrastructure
Scalable Data Warehouse (Redshift)
We initially chose MySQL as our data warehouse because it’s a system our engineers know how to optimize well. However, because MySQL is row-based, it’s not built for aggregation queries with complex joins over massive datasets. When we hit performance problems, we adjusted indexes; when we hit more performances problems, we built a custom histogram-oriented query caching layer on top of MySQL.
Still, each optimization only got us so far, and we didn’t want to spend our valuable engineering resources building an analytics database. Many companies have published that Redshift gave them great speedups, and so we decided to experiment with it. The results have been fantastic. In the extreme case, a daily query we tried on MySQL took six hours; on Redshift it took a few seconds without any modifications!
The Migration Process
Migrating to Redshift was no small feat. Our existing data pipeline was built with MySQL in mind, and everyone was familiar with it. We put in a lot of up-front effort to abstract out a lot of the Redshift-specifics, like loading data via S3 and merging data into an existing table while respecting primary keys. The lack of support for primary keys was the biggest unexpected cost. Then began the fun of migrating our existing data pipeline. Complex dependencies meant we had to be careful to migrate writes in the correct order. We had to double-write to MySQL and Redshift for some time while we migrated all the queries that read from a table from MySQL to Redshift. Coordinating the cross-organizational efforts to migrate the huge number of interdependent MySQL queries, some of which were used and understood by very few people, was the hardest part. We got great feedback from the data science and business teams on their main friction points, and made them less painful.
Unlocking new analysis
While our primary objective when we chose Redshift was to solve performance and scalability issues, it also made huge contributions to accessibility. This came somewhat unexpectedly and indirectly. We had been looking into BI tools around the same time we were migrating to Redshift. We evaluated several tools and liked Looker the best, and decided to give it a try. Unfortunately, analysis was too slow for us to recommend it to our business team when we hooked it up to MySQL. Connecting Looker to Redshift changed the performance profile from many minutes to being able to iterate on most queries in real-time. The combination has been so powerful that the business team essentially adopted it all by themselves. Most of our business team are now able to explore data by themselves, even those who don’t have any familiarity with SQL queries. Even better, they are able to do this without needing any help from the data infrastructure team. Their team lead says “It’s like I just traded in my 1995 manual Jeep Wrangler for a Ferrari…. it’s so much faster and more fun!”
Scaling Further
Redshift also provides tools to limit resources for individual processes and applications. We’ve made heavy use of these to prevent individuals from rendering the database unusable by others. With a click of a few buttons we can speed things up and increase storage in half an hour by increasing the number of machines. We might even scale this automatically in the future.
Scalable Log Processing (Elastic MapReduce)
Our daily data processing latency was getting longer and longer, and we were scrambling to keep it under 24 hours. While Redshift helped a lot, we needed to scale the log processing part too. We decided to go with the longtime-industry standard Hadoop MapReduce. Besides being easy to scale, it is also an easier way of thinking about a lot of data processing. Combined with our efforts to build a framework that was really easy-to-use, this led to more people whose day job is not writing code being able to process raw logs into useful information. Thus, this was both a big scalability and accessibility project.
We built our framework on top of Yelp’s mrjob, because all of us knew Python well and it was much easier to get started running jobs on Elastic MapReduce. We knew it was significantly slower than Java and streaming, but that level of performance wasn’t important enough to us to lower accessibility. We designed our framework knowing that we will likely swap out mrjob for something else one day.
When we started using MapReduce, we were still double-writing to both MySQL and Redshift. This initially lead us to loading data into both databases from the Hadoop cluster. This wasn’t working for us though, as most of the cluster sat idle for long periods of time and we would sometimes hit timeouts. So we pushed forward on getting rid of MySQL, and moved the loading of data into Redshift outside the cluster. Amazon’s Elastic MapReduce can store output in S3, and we made use of that to store data and load it into Redshift as a separate job from a single server.
We currently use only 8 node clusters, and that’s given us a 4-6x performance improvement. When our growth team triples the number of running experiments, we can just increase the size of our Hadoop cluster or add more clusters. We run on Amazon Elastic MapReduce, which makes this easy. The scalability also helped with accessibility in a very indirect way: our business team is far more comfortable adding more data processing, without worrying about their code being too slow and negatively impacting our data pipeline.
Business Intelligence Tools (Interana and Looker)
While investigating BI tools, we were introduced to Interana, an interactive event-based analytics solutions that processes raw event logs. While it wasn’t what we were initially looking for, we integrated our data and found it to fill a need we didn’t even realise we had: super-fast iteration analysing raw logs. We became one of their first users (check out their recent launch), iterating with them on their early product design with them implementing a lot of our feature requests, and it is increasingly becoming an integral part of data analysis for our product teams. At the same time, Looker has continued to be a great complement for our business team, who need to analyze the state of the world at specific points in time.
We can process billions of data points in a few seconds. It has opened up a lot more of our data to intense data analysis not possible before. Anyone looking into data patterns can quickly slice and dice data to discover root causes, and sift through segments quickly with access to our full data set. This allows them to explore how our users use the product, from simple event counts grouped by attributes to complex session and funnel analysis. We now rarely create ad-hoc scripts to crawl logs that create specific aggregations. We started using Interana to analyze performance logs. The team say they “became an order of magnitude more effective at finding and fixing regressions once Interana was added to our performance data pipeline.”
Some examples of what Looker is great for:
Querying financial and revenue data; slicing revenue in various ways to understand the drivers of growth
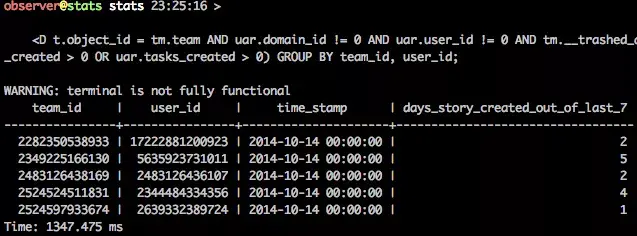
Visualizing cohorts over time (screenshot to the right)
Data dumps; all customers that meet a criteria, etc.
Looker helps us look at ad-hoc cohorts over time for large-scale modeling
Some examples of what Interana is great for:
Interactive funnel analysis
Visualizing which user actions cause performance issues (screenshot to the right)
Understanding what actions users who use the app for long periods at a time take
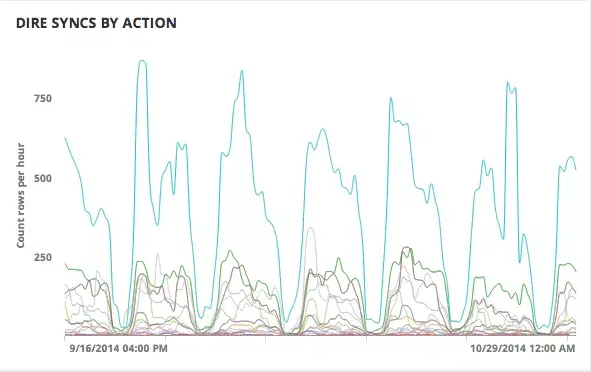
Interana allows us to find which common actions in Asana are slowest most often.
What’s Next
Besides these large projects, we’ve hardened everything to make it more difficult for anyone to accidentally break things. Justin Krause, our business intelligence lead, says “Our lives are all immensely better. I can barely even break things anymore.” Most weeks, we only spend about half an hour maintaining the infrastructure. We love where we are, but this is just a point in a long journey. With growth, new features, and new business needs, many parts of our pipeline will become obsolete in the coming months and years. We know that things will fail in new and interesting ways, and we are adding tests and monitoring to catch many of these before they happen. We are also looking at the fast pace at which new systems are becoming popular in the data analytics space and planning our next moves.
Some things we think we might explore include:
Adding Hive, building something on top of Redshift, or another system for raw log querying outside the scope of Interana’s capability
System for streaming data analysis
Faster Hadoop than mrjob, or possibly using something like Spark for in-memory MapReduce
Better data anomaly detection and trend alerting
Eliminating single points of failure
If you have great ideas on building data infrastructure in a fast changing environment, come join us in the next phase of our journey. If you want to analyze large data sets and understand how teams work together, come use this infrastructure as a data scientist! As Clark Bernier, one of our data scientists, puts it: “Working with a talented and dedicated data infrastructure team is one of the best parts of being a data scientist at Asana. I can stay focused on the numbers and their meanings, trusting that my analyses will run lightning-fast.”