Making Asana Work In Internet Explorer
One of the benefits of working on a brand new product is deciding the cutoff line for supported browsers, and not having to worry about the challenges of supporting older ones. At Asana, we didn’t want to compromise on having a great user experience, so early on we decided to only support the most modern browsers which could handle the needs of our complex Javascript client—the latest versions of Chrome, Safari, and Firefox. The obvious browser missing from the list was IE, which had long been an outlier in terms of developer compatibility and friendliness. Dropping it saved us a lot of time and resources.
 Internet Explorer 10 represents a great leap forward for the IE browser line, with notably better performance, compatibility, and developer support. In fact, the difference is great enough—and so many of our customers wanted it—that we decided it’s time for Asana to grow up and implement first-class support for Internet Explorer 10. We’re proud to report that implementation was a success, and IE10 users can now use Asana!
Internet Explorer 10 represents a great leap forward for the IE browser line, with notably better performance, compatibility, and developer support. In fact, the difference is great enough—and so many of our customers wanted it—that we decided it’s time for Asana to grow up and implement first-class support for Internet Explorer 10. We’re proud to report that implementation was a success, and IE10 users can now use Asana!
We faced a lot of challenges on this journey, the first being that we had absolutely no idea how much work this would be! So, for other teams who are thinking of taking the leap, here is our experience of what it took to get Asana to work on IE.
A comfortable development environment
We’re a Mac and Linux shop, which means we can’t even run Internet Explorer without a special setup. But requiring each developer to have a separate Windows laptop is cumbersome, and it turns out that getting used to the hardware is its own learning curve. So, we looked for a friendlier solution.
We bought a few high-spec Mac Minis and installed VMWare Fusion on them, running Windows 7. The result is that each developer on our team can screen-share into a machine and essentially have IE running in a window on their Mac. There’s a little lag but it otherwise feels pretty good. This also means that if other people at Asana need to test something on IE they can just screen-share the same way—no passing around laptops required. And if we downsize our need for Windows machines we can always repurpose those Mac Minis for something else.
Learning the tools
IE10’s “F12 Developer Tools” is actually a reasonable debugging tool, approaching the Firebug of yesteryear in terms of features and usability. Coming from the pretty amazing Chrome Developer Tools, it took some getting used to.
For starters, F12 does not dynamically update its own representation of the DOM, even as elements are appended and removed. Like most AJAX apps out there, Asana adds DOM elements after the initial HTML has loaded, and element inspection was not working on these dynamically loaded elements.
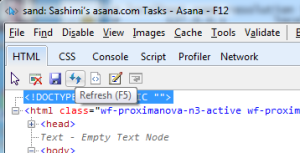
The way to work around this is to click F12’s refresh button (next to the save button) when all the elements have been generated. This does make it difficult to work with elements that get added to the DOM on hover, so it was worth ensuring we had the ability to freeze that state in our app.
Further, adding a debugger statement in the JS is not enough to pause JS execution—one must also click “start debugging” in the script tab. Note—this will refresh the page!
A notable welcome feature of IE that was missing in past versions is a good, reliable stack trace. So now even when we get unfamiliar exceptions or errors, we can track down the line of source where they occurred.
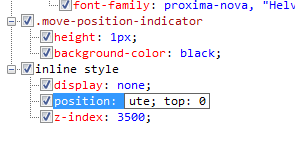
When debugging CSS, we found it impossible to use the UI in an intuitive way to add a new CSS rule to an element. But we did discover a trick: we could edit the value of an existing rule and append a new rule to it. To get the rule to show up in the UI, though, we had to refresh the HTML again.
While these quirks are annoying to deal with, the good news is the upcoming IE11 has significantly improved developer tools which are much closer in quality to Chrome’s. We are looking forward to being able to use them more for our future development on IE.
Coping with stricter JS standards
IE10 is more diligent than many browsers about supporting standards, to the point where it doesn’t support several deprecated ones. For example, IE10+ does not support defineGetter and defineSetter. This type of problem often ends up easy to fix, and it can be a good forcing function to remove deprecated code from the code base. Here is how we got around this particular case—instead of:
View.prototype.__defineGetter__("browser", function() { return this._ui_context.browser;});
we used:
Object.defineProperty(View.prototype, "browser", { get: function() { return this._ui_context.browser; }});
We have also been using Function.name when passing in closures to help with debugging. IE10 does not support this non-standard property. To work around this, we used:
func.toString().match(/^functions*([^s(]+)/)
Tiptoe around elements not in the DOM
Chrome let us get away with a lot more than IE when dealing with Nodes that were not in the DOM. For example, the following code executes just fine in Chrome:
var div = document.createElement(“div”)div.blur(); // does nothingdiv.getBoundingClientRect(); // returns ClientRect with all zeros
IE throws cryptic exceptions in both cases: “Unexpected call to method or property access” and “Unspecified error.” Checking whether an element is actually in the DOM to avoid this crash is easily done with document.documentElement.contains(element) but all the same we believe it would be better for the API to be more tolerant here.
Flexbox? F@$#box!
We have recently started using the flexbox layout model that allows for very powerful dynamic centering and scaling. Flexbox is not yet standard, so it requires browser specific css such as: -ms-flex-direction: column;
This was made a lot easier by using mixins in a CSS manager like SASS or LESS (if you’re not using one of these, you should be), which means that we could fix everything in one place.
For reference, here is the flex box mapping that we’ve had to add:
display: -webkit-box; display: -ms-flexbox;-webkit-box-orient: vertical; -ms-flex-direction: column;-webkit-box-flex: 1; -> -ms-flex: 1 0 auto;-webkit-box-align: $align; -ms-flex-align: $align;-webkit-box-pack: $pack; -ms-flex-pack: $pack;
IE is somewhat flexbox-friendly—but it has its quirks.For one thing, we discovered some bugs when child elements were added or removed from a flexbox container. Sometimes IE would simply drop the height to zero and not draw the entire flexbox.Other times, with some layouts it just seemed like IE required more flexing rules in more places (and sometimes those same flexing rules applied in other browsers would give undesired or opposite behavior). This is more a problem with browsers having different implementations than one being strictly better than another. The fact that behaviors are different on all three major browsers, and these differences not clearly documented anywhere we could find, can make using this feature maddening even though it has so much promise.Note, various CSS features will get closer together with IE11. See its Flexbox changes.
Browser-specific prefixes in CSS
Many CSS3 rules require browser-specific prefixes. For many rules, IE10 actually supports the standards, such as box-shadow, animation and @keyframes. We had to audit a lot of our CSS to make sure we were also including each rule by its standard name (and not just its -webkit- and -moz- prefixed names) or its -ms- prefix where the standards still weren’t supported by IE 10. This is another place where using a CSS manager helped a lot.
Making file upload seamless
To achieve a smooth experience uploading files, we want to skip the explicit clicks to open a file picker and submit a form. So we did the following:
- When a user selects the “Attach from computer” menu item, we call
clickon a hidden file input. - We listen for that input’s
onchangeevent to know when the user has selected a file. - In response to that event, we create a
FORMelement, move the hidden file input to it, and then POST the form to S3 (where we host attachments) to upload the file.
This worked great in other browsers, but in step 3 IE denied the posting of the form. It turns out when we invoked click from JS, IE would dutifully run the behavior, but blacklist any form from submitting if it used that input!
There is a workaround for this, which is to have the thing the user clicks on be a LABEL element with a for attribute that specifies the file input. Unfortunately, this requires that the label and file input be in the same form, which puts constraints on the DOM hierarchy that were not easy for us to obey (our attachment menu is a dropdown, which is rooted high up in the DOM). This could be a good solution for other sites, but not us.
Thankfully, Amazon launched Cross-Origin Resource Sharing (CORS) support for S3 a while back, so we switched to using a more standard XmlHttpRequest. This was pretty easy: instead of submitting a form full of hidden inputs, we populate a FormData object, and send it to S3 using an XHR. We had to configure S3 to allow cross-origin requests (which still require credentials, of course).
Selection, or how to build basic functionality from scratch
Our description and comment fields are dynamic editors and contain tokens (such as links to other tasks) whose contents may change. We must be able to re-render part or all of them in response to changing data. This often means we must destroy and re-create the user’s selection after we re-render. IE10 does not support setting the direction of a selection the way other browsers do, meaning we could not properly restore the selection if a user was selecting backwards with the keyboard. This, admittedly, is not a common problem for other developers, but the assumption that we could do this is built deeply into our reactive framework. And it meant we had to re-implement something the browser ordinarily takes care of—keyboard selection—completely from scratch.
This is difficult stuff, even without all of the corner cases. We needed to implement growing and shrinking selection in all the ways a user might achieve it:
- by character (Shift + Left/Right)
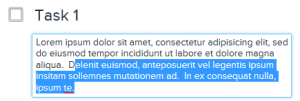
Selecting up by line in the Description field. - by word (Shift + Ctrl + Left/Right)
- by line (Shift + Up/Down)
- and by page (Shift + PgUp/PgDn)
Of course, we also had to ensure that if the user selected with a mouse we would be in the right state to extend the selection with the keyboard.
The way we achieve all this could go into a blog post all its own, but suffice it to say it’s non-trivial. We can get the client rects of the current selection using range.getClientRects() and then iterate over characters to calculate when we’ve moved up a line, or a page. Unfortunately, there are lots of gotchas here. For example:
- If the user has selected a blank line, we don’t always get a rect for that part of the selection, so our app may (sometimes) think there is one less line selected than there really is.
- Some selections don’t always yield rects at all (e.g. with a collapsed selection), so sometimes we have to insert an empty span, get its client rect, then remove it.
- We cannot set one part of the selection range to be at the edge of a text node, as IE will just destroy it and the selection will be lost. This means that, although we may frequently read selection or compute it to end up there, we must “canonicalize” it first, i.e. push the selection up to the correct offset in its parent node.
In the end, we were able to surmount most of the issues and roll our own reasonable selection experience. In fact, we’d like to think if we didn’t mention it in this blog post, no one would ever know.
Contenteditable
The contenteditable attribute causes the browser to treat an HTML element as “editable” by the user, opening the door for rich text editing capability. We use a limited version of this in our description and comment composer fields. Despite this being a standard, supported attribute, what actually happens when a user makes an edit varies widely from browser to browser. We care about this behavior because we must canonicalize it, serialize it, and re-render it, restoring selection in the right places.
The most significant place of divergence is handling of newlines. Consider the HTML <div> foobar </div>. Now suppose the user presses ENTER between “foo” and “bar”. What will be the resulting HTML on each browser?
Chrome wraps the second line in its own DIV: <div> foo <div> bar </div> </div>IE wraps both lines in P tags: <div> <p> foo </p> <p> bar </p> </div>Firefox just puts a BR in place of the newline: <div> foo <br> bar </div>That’s right, they’re all different. IE isn’t special in this regard—it doesn’t approximate either of the other two browsers’ behavior. They’re all snowflakes. We had to train our app to understand IE’s unique representation of user input, along with all of its edge cases.
Can-do custom scroll bars
There is an ideological debate about whether the browser should be able to control the look and feel of the scroll bars. Firefox doesn’t support toolbar styling at all, and IE only allows changing the color but not size. We should note that no toolbar styling is in the official HTML spec.
However, as we strive to be a desktop-quality app, we need control over the scrollbars. Our left pane’s design calls for very thin scrollbars, so we had to implement our own.
There are a number of custom scrollbar libraries available online, but many of them require jQuery, which we do not use, or come with excessively many features. Ours were based off of Facebook’s custom scrollbars, which they use in the Messages inbox.
This is doable with a bit of a clever hack. Rather than putting the content into a single div with overflow-y: auto; we use two nested DIVs. The parent, which serves as a sort of picture frame, doesn’t actually scroll – it has two rules:
.scroll-container { height: 100%; overflow: hidden;}
Inside of this, we put the child, which has the following rules:
.scroll-scrollable { overflow-x: hidden; overflow-y: auto; width: 150%;}
This DIV actually has a scrollbar, but it’s far off on the side, and won’t be visible behind the .scroll-container frame.
For this to work, though, the contents contained in .scroll-scrollable must have a fixed width.
Fighting for custom fonts
One of the most puzzling issues was that IE would not load the icons we specified in a custom font file. The symptom was that most of the time, the font just did not show up.
An important confounding factor here was HTTPS. We do local development with secure URLs to reduce the number of differences between development and production environments. This induced problems for IE in a number of ways, many of which were red herrings.
First, there was an error message about the certificate (our developer certificate is self-signed). Amazingly, the icon font would load fine if this was the first visit of the session, and what also distinguished the first visit was that the IE untrusted certificate warning showed up. When the user accepted the warning, the icon font loaded. But on subsequent page reloads the warning would not show up, and the fonts would never load.
The Network tab in the developer tools showed the request, but checking the response body for the font file would turn up empty. What did this mean? The Content-Length on the response was right (13k), why was IE reporting no content?
This seemed like a certificate problem—IE was probably refusing to use the content for security reasons. We tried importing the certificate to be a trusted root for development. This fixed all the certificate warnings in the UI and the log, but did not fix the font.
The next step was to set up a dead-simple test environment, just an HTML page with tags to include the fonts and output one of the glyphs.
In summary, here are the problems we thought it could have been (based on brainstorming and research), but wasn’t. Each of these took time to think of and investigate:
-
Unsupported use of ligatures (to diagnose: used fontsquirrel to see if a random font from there worked)
-
Untrusted certificates (to diagnose: installed the development certificate as a trusted root)
-
Wrong mime-type on the resources (to diagnose: ensured we were setting the right Content-Type header)
-
Fetching the fonts from a different origin, and not having the Access-Control-Allow-Origin header in the resource response (to diagnose: ensured our server responded to HTTP OPTIONS requests and the GET requests with the proper CORS headers)
-
Problem with HTTPS vs. HTTP (to diagnose: configured our webserver to serve the resources over plain HTTP)
-
Bad TLSv1 handshaking (to diagnose: installed Wireshark or another TCP monitor, configured it to decrypt HTTPS using our cert, captured the requests made for the page, and saw whether the server was in fact sending all the data)
So in the end, what was the problem? IE10 appears to be so strict about caching that when it downloads files over HTTPS and the response contains certain cache-restricting headers, the browser actually prevents itself from reading the files it needs to. This article gave us the idea, and when we removed the caching related headers that we were adding by default in our sandbox, the problem went away. The headers we were erroneously sending were Pragma: no-cache, Cache-Control: no-store, and Expires.
More random tidbits
There are plenty of other gotchas we hit that deserve mention. Here’s a non-exhaustive list of further differences we discovered empirically:
-
Whenever we happened to call
blur()on the body of the page it hid the window behind other IE windows, without losing focus. This is puzzling, and other browsers don’t do this.
-
IE does not support pointer-events: none, which was a really nice workaround when we had one DOM element overlaying another (say, for decoration) but wanted the element in the back to be the one receiving all the mouse events. To let click events pass through an element, we had to use
background-color: transparent, but this meant the top element could no longer add color. -
There is a bug somewhere where setting the selection of a
TEXTAREAsometimes throws an error 800a025e. It didn’t matter whether we calledselect(),setSelectionRange(), orcreateTextArea()and then select the text area, we got the same result. The textarea in question was in the DOM. We never got to the bottom of it, and had to work around it. -
IE10 (like Firefox) does not show placeholder text in inputs if the input has selection. In places our UI design depended on that text, we had to make changes.
- If IE10 has an empty
Ptag, and we callinnerHTMLon its container, the output suggests that there is an text node inside thePtag. This is misleading; there is no such text node. -
When we send an asynchronous XHR to upload a file of size zero, IE10 never completes that upload—so we must disallow zero-sized file uploads on IE.
Maintenance
Supporting a new browser comes with a hidden challenge—ensuring that support doesn’t break over time, as developers add new features and UI. Given that all of our infrastructure runs on Linux or OS X and employees typically dogfood on Mac and Chrome, we’re currently investigating how we can incorporate running our tests on IE as part of our automated testing system. Our automated test framework helps keep our engineers moving quickly while maintaining a stable product, and is the topic of a future exciting blog post!
Summary
The effort to get Asana to support IE10 was full of new challenges, eye-opening discoveries about how different browsers can behave, and the need to account for lots of unknown unknowns. But if a high-performance, JavaScript-heavy app like Asana can work well on IE10, we’re pretty sure anything can.