Testing in production: Rewriting APIs with dark clients

Over the last few years, performance has been a major objective at Asana. Many of our engineering teams are committed to building a faster Asana experience and making teamwork more effortless.
To this end, we’re not only re-writing our web app to be much faster, but also re-writing our public API. Our customers and partner developers build scripts, integrations, and even standalone applications on top of Asana’s API, and we want to ensure a fast Asana experience for them, too. Mobile users also depend on our API, so when our API gets faster, so do our mobile apps. In this post, I’ll describe how our team used dark clients to help us uncover issues and track progress as we developed the new API.
As a rewrite of the old API on top of our new architecture, the newly released fast API had two main goals:
- Improve performance of read endpoints
- Behave consistently with the old API
There are complications that come with rewriting the API that aren’t as prominent in re-writing web components. Developers have built apps that rely on certain behaviors that we need to keep consistent. As of the writing of this post, the Asana API is not versioned. Thus, even small changes to API behavior should be avoided unless necessary, for fear of breaking the apps built on top of it.
To guarantee that the new API behaves as expected, we had the usual barrage of unit tests for individual components. However, we also wanted to ensure that the new API’s behavior matched the old API’s. While normal integration tests could have helped with this, we decided that the best way to ensure the old and new APIs behaved the same way was to send them identical requests and check that the responses matched—which we did using dark clients.
Using dark clients
Basically, a dark client is a “fake” client that sends API requests to an API server. Our dark clients replayed requests received by the old API and sent them to the appropriate dark server to simulate production load. Details about the old API’s requests were logged, and dark clients consume these logs to issue identical requests. Because we only scoped the new API to handle read requests, we didn’t have issues with handling the same requests multiple times.
Dark client requests also had special headers to identify them as dark, so that we didn’t generate additional logging for them. Otherwise, we could have had a particularly nasty infinite loop, as dark client requests generate more logs that are again consumed by the dark clients.
During development, we had two dark clients: a correctness and a stability (load testing) dark client. While the old API was still serving production traffic, we also had two instances of the new API (correctness and stability dark servers) running, which would receive requests from the correctness and stability dark clients, respectively. Our two dark clients/servers: correctness and stability, had different goals (as their names imply). Below, we examine how these were architected in more detail.
The stability dark client
Because the new API was built as part of a major infrastructure change, we wanted to make sure it could handle production load. Thus, the goal for our stability dark client and server was to simulate production-level traffic and identify issues before launching and affecting real users.
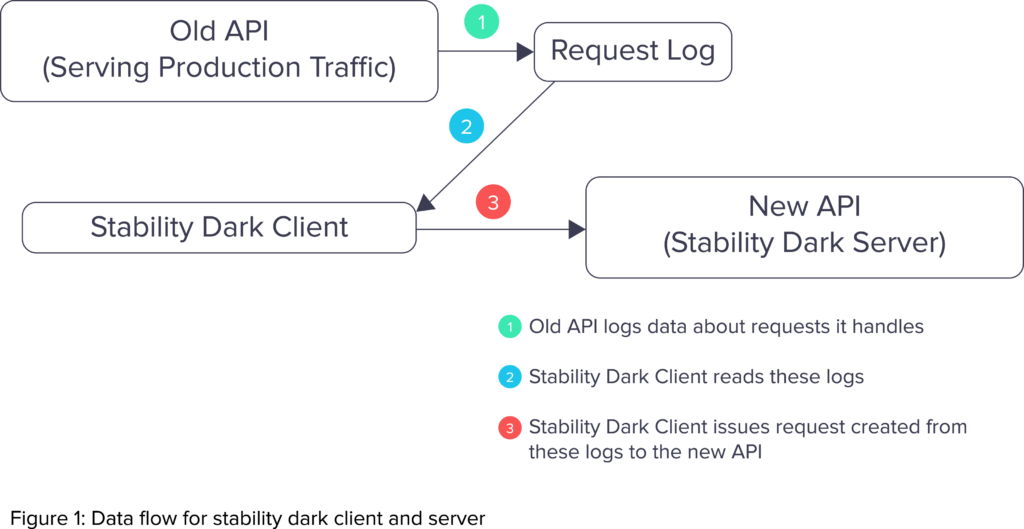
For the stability dark client and server, requests served by the old API were forwarded to the stability dark server. If we noticed that servers or databases were encountering issues, we scaled down the proportion of requests forwarded, often disabling it entirely while we investigated and fixed the issue. Closer to shipping, we raised this to 100% to simulate production load.
The stability dark client identified several issues for us. Early on in the development of the new API, we found that we were putting too much load on our databases.
In response, we routed requests from the same user to the same server. This increased cache hit rates and reduced database load. Finding issues like this before implementing the entire new API helped us find root causes quickly and deal with them effectively. Finally, having the stability dark client load test the new API helped us launch with confidence, knowing that it would not cause production issues.
The correctness dark client
Because we wanted to ensure a seamless transition for our developers, the behavior of the new API had to mimic the old API. The goal for our correctness dark client was to identify discrepancies in output between the APIs.
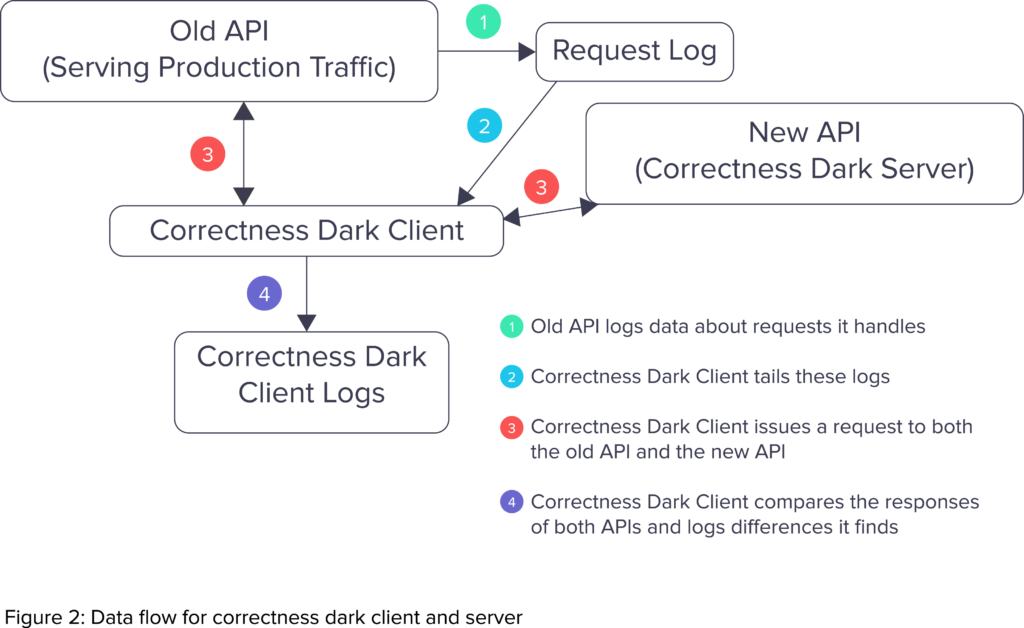
As in Figure 2 (above), to do this, for every API request that it found from the logs of the old API, the correctness dark client would issue an identical request to both the correctness dark server and the old API. Then, it would compare the output of the two responses, ignoring meaningless differences like the order of the keys in the JSON response. If there was a meaningful difference, it would output details about the difference to a log that our engineering team could inspect.
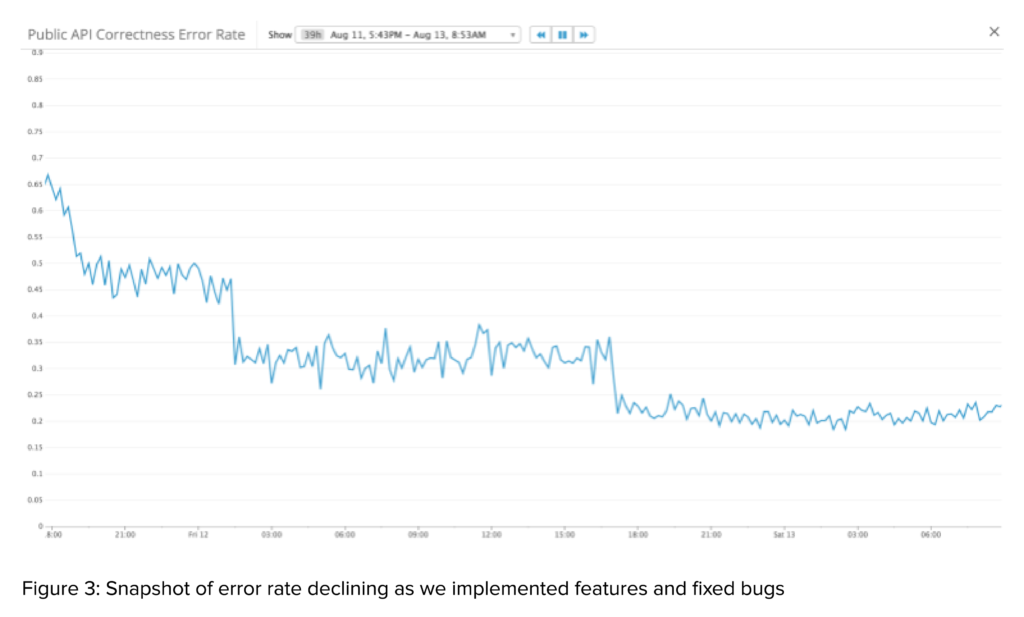
We also used Datadog to track metrics like our error rate (proportion of requests that the new API doesn’t return an identical response to the old API for). Figure 3 shows how the error rate declined as we implemented features and fixed bugs while developing the new API.
This set up gave us a many benefits, including being able to:
- Plot the decrease in our error rate over time. This was a great motivator as we continued to fix bugs and match the old API’s intricacies as best we could.
- Prioritize which bugs to fix, namely the ones that occurred most often in the error logs. This makes sense if we want to minimize the number of differences encountered across all our users.
- Ignore differences that we weren’t going to fix by tweaking the correctness dark client’s response comparison logic. While developing the new API, we discovered bugs in the old API and minor, uncommon behavioral quirks that we decided to deprecate in the new API. We also decided that we didn’t need to be consistent on inconsequential differences like JSON key order in the API response.
Future plans for the dark clients
Now that the new API has shipped, we have the opportunity to repurpose the dark clients for more use cases. One idea is to use the correctness dark client to compare the output of the beta and production deployments of the new API. That way, we can recognize correctness bugs in beta before they hit production and take the appropriate actions.
Another use case for the correctness dark client is performance comparison. In the next few months, one of our objectives is to quantify how much faster the new API is compared to the old API. Our correctness dark client can help us achieve this by timing the requests to both the old and new API, and providing detailed round-trip performance metrics.
Summary
Regardless of how we use the dark clients in the future, they were very helpful in getting the new API ready for production. The dark clients were able to flag certain issues that standard unit/integration testing has trouble finding, and gave us great ways to chart our progress in developing the new API as our error rate gradually decreased. In the future, we plan to continue using dark clients to identify regressions between beta and production, and, more generally, simulate activity whenever echoing realistic API usage would be beneficial.