Part 2 – WorldStore: Distributed caching with Reactivity

This post is the second in a two-part series on how we implemented distributed caching in a fully reactive framework. Read Part 1 before reading this article.
Last time we talked about why we needed to add distributed caching, and where it fit into our infrastructure. Picking up from there, in this post we’ll jump into how we designed and implemented the specification, and scaled it to meet production requirements.
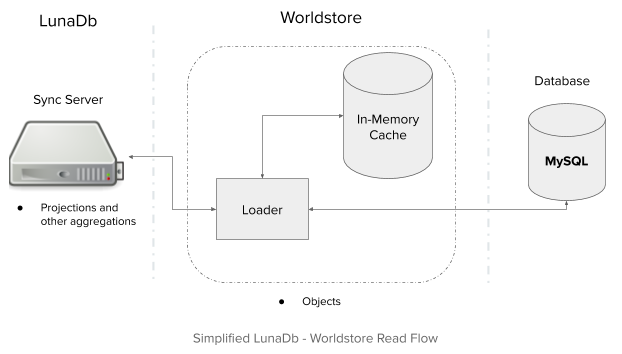
Adapting Cache Invalidation
To understand the challenges here, we have to delve a bit deeper into the design details of the invalidation pipeline. In particular, let’s take a look back at how it solves key issues in implementing data reactivity:
1. How does a system keep track of every piece of data a client is subscribed to, for every client?
We maintain per-client data subscriptions on sync servers (in-memory). We can:
- Add subscription entries (ie. when loading a page, or opening a task pane)
- Remove relevant subscription entries to reflect clients unsubscribing from data (ie. navigating away from page)
- Refresh a subscription entry (ie. when data has changed)
2. How does a system determine which data has potentially changed (ie. the effects on the work graph)?
Invalidators tail the replication log of a database. Based on the observed data changes, they query the database to find all affected data in the work graph, and generate corresponding invalidations. These invalidations describe all the data that should be invalidated and refetched.
3. How does a system notify all subscribers of some data that has changed?
Sync servers simply tail the invalidation streams from all databases. The invalidator continually streams invalidations. Each invalidation is a notification of a specific set of data that has changed.
The details for determining changed data are intentionally a bit vague—and that’s because the actual implementation relies on a more complex abstraction called a topic1. Although the full details of topic generation are out of the scope of the post, we can define a topic as an encoding of a set of data requests. More formally, we can discuss the design with regards to the following characteristics:
- Topics are generated from a pure function on a data request alone, which means that a set of topics generated for the same data will always be equivalent, even if created by different servers.
- There is a many-to-many relationship between data requests and topics. In short, a single request may be described by multiple topics, but those topics may not be unique to this request
- Topic generation is effectively one-directional, i.e. we can easily generate the set of topics for a single request, however, the set of data requests a single topic is created from may be infinitely large
For managing subscriptions, sync servers maintain mappings of topics to data. Correspondingly, generated invalidations contain sets of topics to invalidate. Upon receiving an invalidation, a sync server updates the relevant subscriptions. Additionally, sync servers also have data caches that are keyed by object identifiers. As a result, sync servers also invalidate the corresponding elements of the cached data.

This invalidation pipeline worked for the local caches in sync servers, but adding in a distributed cache presented additional challenges and constraints. Primarily, there’s no guarantee that data in the distributed cache is as up-to-date as the requesting sync server. Secondarily, the invalidation pipeline requires that we have a cache that is both indexable by object, but is also “invalidatable” by topic.
With these constraints in place, we can outline a basic system, and leave out the specific details of the components in question. We can then consider a series of strawman proposals, and adapt a working implementation that fits our constraints.
Design Process
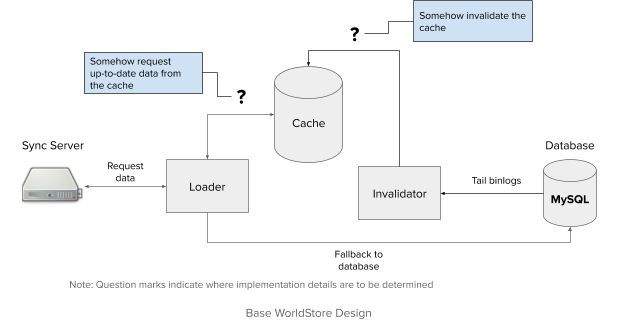
A basic design would consist of a loader and an in-memory store. The in-memory store would be directly invalidated by a process on an invalidator. The sync server would make data requests to the loader, which would attempt to use the cache, or fallback to the database.
Proposal: Using BSNs as version checkpoints
Let’s consider an approach that uses binlog sequence numbers or BSNs as version checkpoints in our system. The idea is to use these version checkpoints to check how relatively up-to-date a requesting sync server is in comparison to a cache entry. Sync servers would make requests to the loader with a version checkpoint, representing their progress in consuming their respective invalidation stream. They would expect to receive data that is at least up to date with the requesting BSN.
Unfortunately, since BSNs represent a global version, they change on any database transaction. Why is this a problem? Let’s take a look at a simple example:

- Assume a simple cache where data is stored by id along with a version checkpoint
- If data is cached at an earlier BSN, we don’t have sufficient information to know if it’s up-to-date
As a result, while they technically allow us to check if data in the cache is up-to-date compared to a client, using BSNs alone would cause cache thrash since we would frequently discard usable cached data. To mitigate this, we would need to enforce two invariants:
- The invalidator must always have invalidated the cache for a version checkpoint v before the sync server requests data from the loader at version checkpoint v
- The invalidator must invalidate every related entry in the cache during each invalidation
Looking back at the prior example, if these invariants were enforced, we would know that Task A in the cache was usable for the client request because:
- The cache has been kept at least up to date with the client by the invalidator
- If Task A had changed after the version at which it had been cached, then the invalidator would have removed it from the cache. The fact that the entry remains, tells us that the actual data has not changed since it was cached
We can observe that the first invariant can actually be relaxed by adding another check. Just as the sync server maintains its current version checkpoint (via BSNs), so too can the cache maintain its own cache version checkpoint. The cache version checkpoint corresponds to the latest BSN of which the cache is up-to-date with, and will be maintained by the invalidator. We can simply check if the cache version checkpoint is at least as high as the client request version checkpoint.
The second invariant is a bit more tricky. If we refer back to the properties of topics, we cannot reliably compute the entire set of data related to a topic, because the set may be infinite. Instead, we need some other way of invalidating all cache entries related to a set of topics to invalidate.
Let’s call this set of topics to invalidate Tinv. A naive solution would be to iterate over each cache entry, compute the set of related topics, and remove each entry whose set of topics overlaps with Tinv. However, this procedure would be prohibitively expensive, and wouldn’t scale to the rate of invalidations. Ideally, we need some method of invalidating cache entries with O(size(Tinv)) complexity. Let’s reconsider known properties of topics generation, and see if we can maintain a different set of data on the cache that is efficiently searchable by topic.
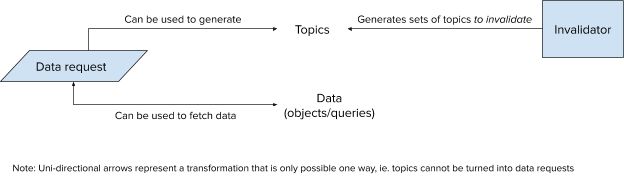
We can observe that the data naturally lends itself to maintaining not one, but two different mappings, a data mapping, AND a topic mapping.
Proposal: Tracking Data and Topics
Let’s consider an approach that maintains a separate data and topic mapping:
- A data map which maps data identifiers to both the cached data and version
- A topic version map which maps topics to the version checkpoint at which any associated data entry has been entered into the cache
Additionally, we carry over the cache version checkpoint from the previous proposal. Using this value, we can introduce a new idea: version windows. The invalidator removes all entries from the topic version map when the data they associate with is modified. As a result, we can infer that for a given topic t with version vA and a cache version checkpoint vB, if t exists in the topic version map, then the data associated with it must not have changed between version vA and version vB. This is the basic idea of a version window. Maintaining this mapping allows us to compute the version window for any topic.
In this system, the loader:
- Generates the topics for the data
- Requests the cached data and version from the data map
- Requests the version checkpoint for each generated topic and the cache version checkpoint
- If a topic doesn’t already exist, then we create a new entry for it with the current cache version checkpoint
- Assemble version windows for all the topics
- Compute the intersection between the version windows. This is the effective version window for the data
- Based on the request, the cached data version, and the effective version window, decide if this is a cache hit or miss
- A cache hit means returning the cached data, while a cache miss means falling back to the database, and writing an updated entry to the cache before returning.
An example cache hit/miss decision tree on the loader would look like this:
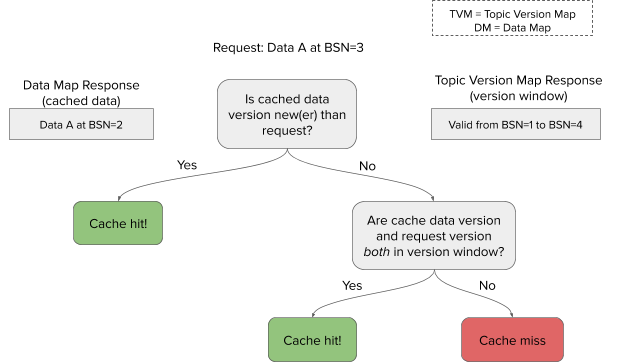
The invalidator only maintains the invariant on the topic version map, ie. it deletes topics as they are invalidated.
In practice, we use two different Redis instances to implement these mappings, referred to as the data cache and the topic version cache (a.k.a TVC). We could theoretically use a single Redis node for both, but in practice these two caches have quite different load patterns that can be optimized for.2
Scalability
This architecture is a simplification of production infrastructure with single components.
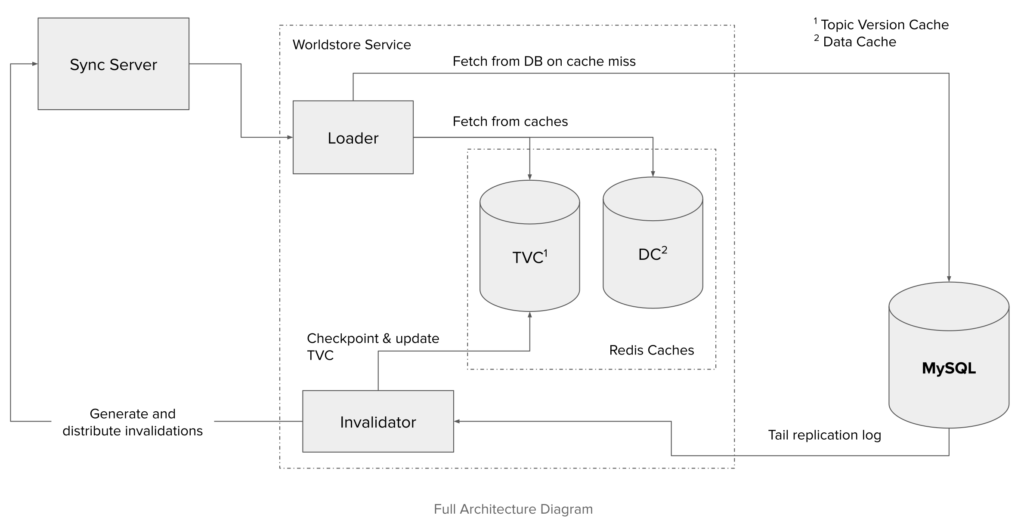
In production, loaders (which are relatively stateless) easily scale horizontally, which also allows downstream consumers to scale similarly. Additionally, other services in our infrastructure should be able to also connect to loaders in lieu of the database.
We typically run only one invalidator per database. To handle the fanout of requests/streams from pubsub consumers, we use invalidator router servers as a GRPC intermediary between sync servers and invalidators.
WorldStore data caches are simple key-value stores, and can easily scale horizontally. Key-to-shard routing here can be done without any major stability or performance compromises being made. However, topic version caches have dependencies between keys in the same domain. Evaluating each request at the loader requires potentially fetching multiple TVC entries. Ideally, we want to avoid talking to multiple TVC nodes to evaluate a single request. To enforce this, topic version caches follow a custom sharding pattern.
The base strategy we adopt is of database splitting. If the invalidations for a single database are split across a reasonable number of Redis instances, then if a single instance fails the blast radius is limited to a fixed small percentage of the database’s traffic. We extend the idea a bit further, and establish a many-to-many relationship between databases and TVC shards. The TVC entries for each database will be sharded across n TVC instances, ie. if a single TVC instance dies, at most a ratio of 1/n additional requests will reach the database. Each shard will contain data from up to m databases, limiting the per-shard fanout of databases to m. We can reconfigure our sharding pattern to optimize both these parameters as necessary.
Additionally, there exist a set of dangerous topics—topics that are related to a large number of requests. If any of these “hot” keys are evicted from a topic version cache, or if the node containing one were to crash, an extremely large number of cache entries would be invalidated. As a result, we cannot simply shard them. Instead, we replicate “hot” keys across every TVC shard that contains data for a given database.
Evaluation
Splitting up these services and adding a persistent caching layer largely yield the intended benefits. Although in-memory caching for sync servers is still used, we are no longer solely dependent on it to protect the database. As a result, we can redeploy LunaDb more times during the day, even during peak traffic periods. Additionally, WorldStore is not as tightly coupled to the web framework, so web app changes can be deployed independently of WorldStore changes.
Similarly, we no longer have a strong dependence on cache warming. Although it is still used, cache warming is now purely a performance optimization and not a requirement for a healthy system. As such, in-memory caches can be smaller, and cache warming can be shorter, which means faster deployments and rollbacks.
Since Worldstore has been fully deployed, aggregate data from production shows that we have a between 70-80% cache hit rate. We are now able to deploy our code to production multiple times per day, including during the morning traffic peak.
Implementation and Deployment
This design covers the majority of the interesting challenges we faced while developing and deploying WorldStore. There were, however, some subtle issues that did not easily translate from design to implementation.
Our biggest concern when deploying this change was the risk of cache corruption. Incorrect code, configuration or deployment could possibly cause a Redis cache to hold data that is different from the database. Cache inconsistency issues could have serious end-user impacts like different users seeing different data, users unable to access their own data, users seeing changes reverted, and various other classes of issues with the API.
We took a couple of safety precautions to mitigate this class of issue. First, we started double reading a small percentage of requests from the loader and the database. If we saw elevated rates of data mismatch here without any lag in our invalidation pipeline, it would indicate that there was potential cache corruption. Additionally, the code was deployed in beta and then in production with an in-code configurable fallback for around six months. During this time we built out tooling and playbooks to better diagnose these issues, encountering and solving a few cache inconsistency issues along the way.
Future Work
Building out WorldStore was a large endeavor that greatly benefited the scalability of our core infrastructure. However, there’s still a lot of performance work left. To that effect, we’re already working towards changes that will allow us to isolate expensive user actions and greater siloize internal components of our infrastructure. These changes, among others, will enable us to effectively scale to much larger peak traffic loads, decrease our reactivity lag, and make our infrastructure much more resilient to unusual traffic patterns.
1Topics are part of a non-trivial optimization to decrease the amount of work the invalidator must do to compute and transmit the set of data affected by a change. It is related to a constraint of our system that generated queries should form a non-empty prefix of the fields in our custom index tables to avoid inefficient queries against the database.
2As a side note, another approach we could have considered (but did not) was maintaining an index from topics to data entries. The main difference would be that this approach would require atomicity of operations between the topic index and data map to maintain correctness. As a result, they would have to both live in a single cache.