Great data: It’s all in the delivery
Great data is about people, not numbers. It’s about driving smart decisions and motivating the right behavior in teammates. Great data is as much about delivery as it is about the data itself – because in the age of big data, getting numbers is easy…. making it all mean something is an entirely different challenge.
Piggybacking on our recent blog post about our data infrastructure, we’re excited to share some of things we’ve learned about leveraging data for business intelligence at Asana: the tools and tactics we use to deliver actionable insights, the way we build playgrounds instead of SQL queries, and we’ll even share some of our most useful visualizations.
Every organization is competing on both strategy and execution – making the right choices, and successfully acting on them. Data informs both parts of this, and ultimately, teams that win do so with great data.
Here is our approach to collecting, exploring, and delivering business intelligence at Asana.
Step 1: Copious Collection (and Connection)
Before we start analyzing, we need data to work with – and it needs to be relevant to our questions or goals at hand. We seek to collect as much data as we could reasonably expect to need – before we need it. Much of our data is related to product usage and state, but we also bring in data from 3rd party systems.
The important thing is that all this data is in one place – our centralized stats database (Redshift). It doesn’t matter if it’s data that originates from our production database, event logs, error logs, billing system, marketing automation system, or CRM… we know that it has to be together to be meaningful.
First party owned data is simply the only way to achieve true business intelligence – if we can’t join data from different sources, we can’t answer questions like:
- Is our marketing campaign delivering quality users?
Requires joining ad attribution data onto engagement data - Are our customer success programs successfully driving revenue expansion?
Requires joining lists – probably in our CRM – with engagement and billing data - Did our most important customer just hit a bad bug, and we need to reach out?
Requires joining error/bug logs onto customer data
Data teams often forget that there is a whole universe of context about users beyond the logging system that’s been set up in the product. Collecting copious amounts of data involves connecting a myriad of systems and bringing data inhouse. It’s difficult work – but an absolute requirement of great intelligence.
Step 2: Enable Exploration
Once we have all the data we need in one place, it’s time to start figuring out what it all means. We’ve discovered a problematic organizational pattern that often happens at this point – data consumers need insights, and they ask for a “dashboard.” We spend tons of time building it, and then we immediately forget it exists – it’s not useful, because we didn’t know what we really wanted.
The part that’s missing in this pattern is exploration – giving data consumers exposure to what is available, letting them discover real drivers, and allowing them to “play around” with as many vectors and data points as possible.
The goals of the exploration phase are simple:
- Get data into the hands of people with domain knowledge
- Lower the technical bar for self-serving data
- Use a flexible tool that makes collaboration, visualization, and sharing insights easy so that teams can discover the right metrics to be rallying around
Our main tool for data exploration is Looker, a BI tool that connects to our stats database. The alternative to a BI tool is a team of analysts doing one-off queries for all the questions our team can ask – which is an infinite number of questions. This is slow, exhausting, demotivating for both askers and analysts, and it ultimately doesn’t scale: different teams end up looking at different numbers from different systems and processes – and organizational intelligence suffers.
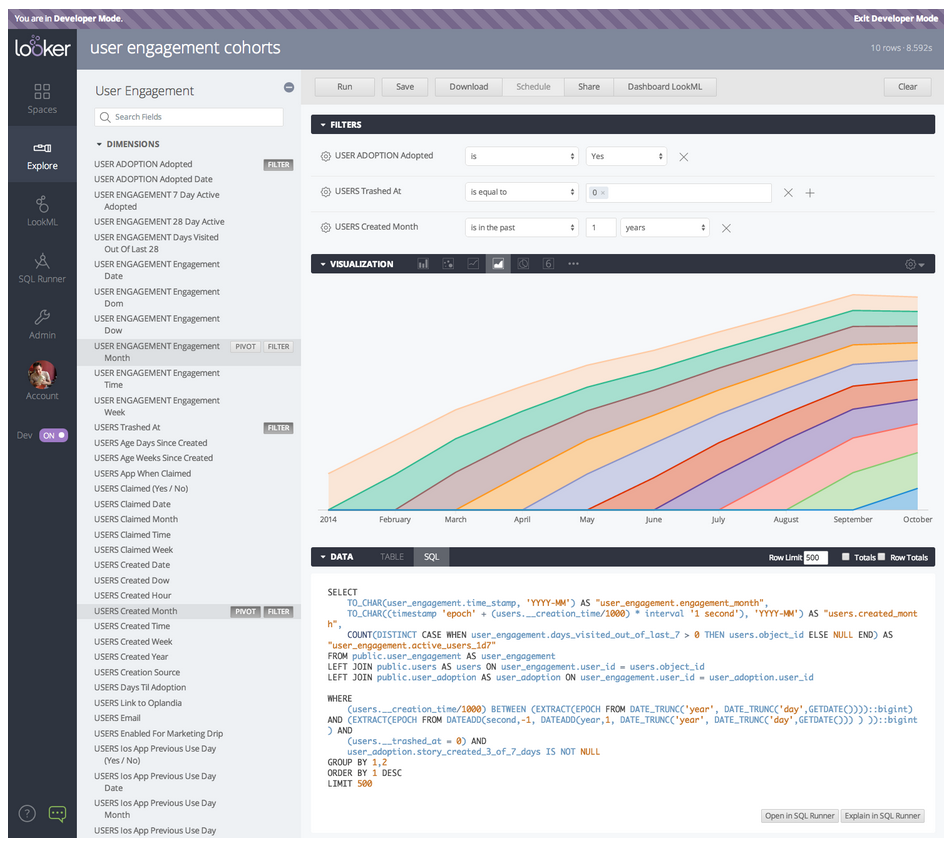
Looker – which is a fantastic BI tool – allows us to build a “model” around our data, centralizing definitions, sharing views, and adding meta-data. Instead of writing queries all day, we can focus on building out the model. Building a playground is a lot more fun than writing SQL.
Step 3: Drive Decisions with Great Delivery
Once we understand the metrics we want to track, we can build out reporting – usually in the form of dashboards. Our goal here is to drive great business decisions – illuminating opportunities in our sales pipeline, tracking our marketing campaigns for cost efficiency, and disaggregating growth so that we can understand the different components and levers.
In our experience, this part simply has to be custom – no third party tool will ever match our specific requirements around presenting and delivering our data. For example, we have specific requirements around smoothing and adding event annotations to our most important dashboards.
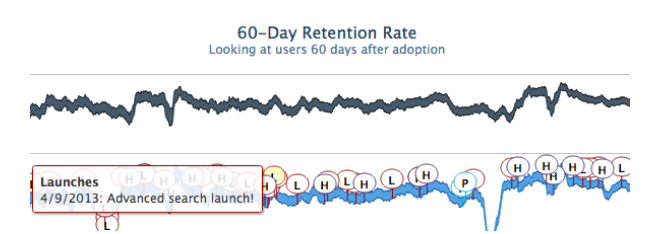
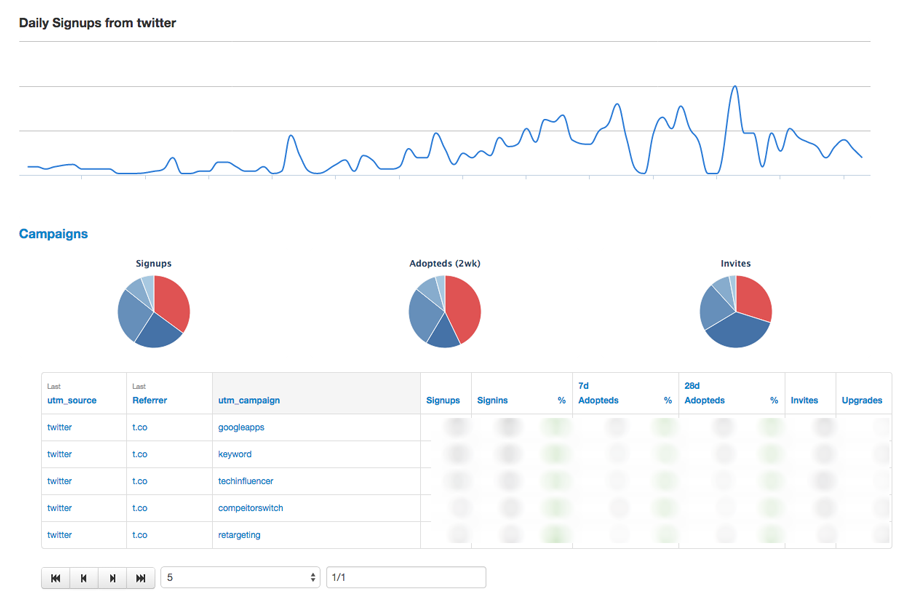
We’ve identified two major types of dashboards – aggregate and parameterized. Aggregate dashboards are pre-generated each night; they are primarily tracking major metrics and trends. Parameterized reporting is generated on the fly using templates for specific objects or categories. We built an internal app where we can search for customers, apps built on Asana, marketing campaigns, even cities – and immediately generate a dashboard. We also have a tool for looking at the results of experiments – another example of parameterized reporting.
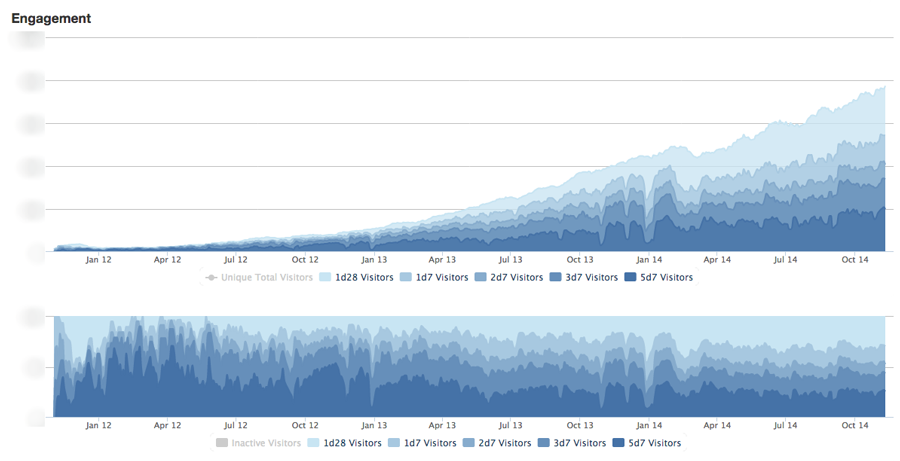
For critical data that we need to track daily or even hourly, we use push mechanisms such as email or Asana. Every day, our marketing team gets an update on top of the funnel metrics like sign-ups, invites, and referral sources – to keep the team laser focused on acquisition and what’s driving results. Our customer success team gets Asana tasks assigned to them when major customers hit triggers around potential upgrade or churn – this not only alerts them but assigns responsibility so that we can make sure someone takes action.
Simply being mindful of the differences between aggregate/parameterized and push/pull reporting – and choosing the right delivery mechanism for the need at hand – has been tremendously important as we work towards better business intelligence.
Other Key Lessons We’ve Learned About Delivery
Mark Twain said, “There are three kinds of lies: lies, damned lies, and statistics.” At Asana, we try to ensure that our statistics aren’t lies, but we also try to be mindful of the power that data has to shape psychology and decisions. We’ve learned (and re-learned) a few lessons on our journey about delivering good data:

- Choose metrics wisely. Pick metrics that teams can move. Avoid vanity metrics. You should have a reason for including every number or graph on every one of your reports.
- Rally around a few core metrics. More data doesn’t equal more intelligence – often it is the reverse. Lazy data teams think that exposing *all* the data will enable perfect intelligence. More likely, it will cause confusion and analysis paralysis.
- Remember your audience. Your growth teams may find tremendous value in sampling, standard deviations, and statistical significance, whereas your finance team may need exactitude. Build reporting that respects the needs of each individual team or consumer, while also maintaining consistency around definitions and data sources.
- Discoverability is a key part of delivery. For every data project, ask, “can we reuse this analysis?” and “how can I make this discoverable?” Putting all our major reporting in one central portal has been critical to getting our team to rally around metrics and feel confident about where to look for insights.
Search is an incredibly important part of enabling discoverability of parameterized reports. This is how we’d look up a customer in our system. - There’s no substitute for domain knowledge. We utilize a matrix structure at Asana, where data analysts are embedded in the teams they serve – so that when marketing asks for something, the data person who responds really understands the question, context, and priority of the request.
The Bottom Line
According to either Spiderman or Voltaire, “with great power comes great responsibility.” Data people stand at the intersection of information and action, and they can have a tremendous impact on organizational outcomes. Data scientists should start to think more like social scientists – and be aware that how we deliver data affects understanding and decision-making.
With copious collection into a first party owned data warehouse, a flexible playground in which data consumers can explore and hone in on insights, and thoughtful reporting on a core set of metrics, great business intelligence can drive great business decisions and support growth.
All it takes is great delivery.
A huge thanks to Asana data people past and present: Jack, Alex, Rachel, Spradlin, Marco, Kris, Graham, and RJ for mentorship, code reviews, and endlessly learning new things.